HTTP/HTTPS 分片
TCP分段与IP分片
1、首先根据Ethernet II类型以太网帧格式可以得知,Ethernet II类型以太网帧的最小长度为64字节,最大长度为1518字节。(另外还有7字节前导同步吗+1字节帧开始定界符是所有类型的以太网帧格式必要的)
以太网帧格式有四种类型,Ethernet II类型以太网帧格式是我通过WIRESHARK抓包后发现目前网络使用的帧格式类型。


Ethernet II帧格式
一开始我有个问题就是,根据TCP/IP的传输流可以知道,HTTP响应报文是装到TCP报文的数据区,TCP报文又是装到IP报文的数据区,而最后IP报文是装到以太网帧的数据区中。为什么以太网帧的数据区最大长度为1500字节,而HTTP报文最终是放在以太网帧的数据区中,却没有限制HTTP报文的大小?
2、在WIRESHRAK抓包的时候会发现很多长度为1514的TCP报文,但是这个跟以太网帧的数据区最大长度为1518字节有什么关联吗?而且这个TCP长度为什么是1460而不是1500 ?

以太网封装IP数据包的最大长度是1500字节,也就是说以太网最大帧长应该是以太网首部加上1500,再加上7字节的前导同步码和1字节的帧开始定界符,具体就是:7字节前导同步吗+1字节帧开始定界符+6字节的目的MAC+6字节的源MAC+2字节的帧类型+1500``+4字节的CRC校验。
按照上述,最大帧应该是1526字节,但是实际上我们抓包得到的最大帧是1514字节,为什么不是1526字节呢?原因是当数据帧到达网卡时,在物理层上网卡要先去掉前导同步码和帧开始定界符,然后对帧进行CRC检验,如果帧校验和错,就丢弃此帧。如果校验和正确,就判断帧的目的硬件地址是否符合自己的接收条件(目的地址是自己的物理硬件地址、广播地址、可接收的多播硬件地址等),如果符合,就将帧交“设备驱动程序”做进一步处理。这时我们的抓包软件才能抓到数据,因此,抓包软件抓到的是去掉前导同步码、帧开始分界符、CRC校验之外的数据,其最大值是6+6+2+1500=1514。
再说一下TCP报文内部的结构。
一个完整的数据包格式,是数据帧{IP包{TCP或UDP包{Data}}},如前所述{IP包{TCP或UDP包{Data}}}部分最大是1500字节。那么根据目前的IPv4协议,有如下规定:
IP首部,版本:4 ,包含源、目的IP、首部校验和,TTL等,共计20个字节。TCP首部,包含源、目的端口,一系列指针、标志、校验和等,共计20字节,因此实际可用的数据为1500-20-20=1460字节。
上面就解释了抓包中的1514和1460的来历。简单来说就是1514指的是以太网帧去除掉一些符号位后的最大长度;1460指的是以太网帧的数据区去除掉TCP和IP的首部后所能存储的最大数据长度,即是HTTP的整个请求或者响应报文。
3、最后再来回答为什么以太网帧的数据区最大长度为1500字节,而HTTP报文最终是放在以太网帧的数据区中,却没有限制HTTP报文的大小?
TCP分段与IP分片
我们在学习TCP/IP协议时都知道,TCP报文段如果很长的话,会在发送时发生分段,在接受时进行重组,同样IP数据报在长度超过一定值时也会发生分片,在接收端再将分片重组。
我们先来看两个与TCP报文段分段和IP数据报分片密切相关的概念。
MTU(最大传输单元)
MTU前面已经说过了,是链路层中的网络对数据帧的一个限制,依然以以太网为例,MTU为1500个字节。一个IP数据报在以太网中传输,如果它的长度大于该MTU值,就要进行分片传输,使得每片数据报的长度小于MTU。分片传输的IP数据报不一定按序到达,但IP首部中的信息能让这些数据报片按序组装。IP数据报的分片与重组是在网络层进完成的。
MSS(最大分段大小)
MSS是TCP里的一个概念(首部的选项字段中)。MSS是TCP数据包每次能够传输的最大数据分段,TCP报文段的长度大于MSS时,要进行分段传输。TCP协议在建立连接的时候通常要协商双方的MSS值,每一方都有用于通告它期望接收的MSS选项(MSS选项只出现在SYN报文段中,即TCP三次握手的前两次)。MSS的值一般为MTU值减去两个首部大小(需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes)所以如果用链路层以太网,MSS的值往往为1460。而Internet上标准的MTU(最小的MTU,链路层网络为x2.5时)为576,那么如果不设置,则MSS的默认值就为536个字节。很多时候,MSS的值最好取512的倍数。TCP报文段的分段与重组是在运输层完成的。
到了这里有一个问题自然就明了了,TCP分段的原因是MSS,IP分片的原因是MTU,由于一直有MSS<=MTU,很明显,分段后的每一段TCP报文段再加上IP首部后的长度不可能超过MTU,因此也就不需要在网络层进行IP分片了。因此TCP报文段很少会发生IP分片的情况。
再来看UDP数据报,由于UDP数据报不会自己进行分段,因此当长度超过了MTU时,会在网络层进行IP分片。同样,ICMP(在网络层中)同样会出现IP分片情况。
总结:UDP不会分段,就由IP来分。TCP会分段,当然就不用IP来分了!
另外,IP数据报分片后,只有第一片带有UDP首部或ICMP首部,其余的分片只有IP头部,到了端点后根据IP头部中的信息再网络层进行重组。而TCP报文段的每个分段中都有TCP首部,到了端点后根据TCP首部的信息在传输层进行重组。IP数据报分片后,只有到达目的地后才进行重组,而不是向其他网络协议,在下一站就要进行重组。
最后一点,对IP分片的数据报来说,即使只丢失一片数据也要重新传整个数据报(既然有重传,说明运输层使用的是具有重传功能的协议,如TCP协议)。这是因为IP层本身没有超时重传机制——由更高层(比如TCP)来负责超时和重传。当来自TCP报文段的某一段(在IP数据报的某一片中)丢失后,TCP在超时后会重发整个TCP报文段,该报文段对应于一份IP数据报(可能有多个IP分片),没有办法只重传数据报中的一个数据分片。
所以之所以却没有限制HTTP报文的大小,是因为在传输层中已经由TCP对HTTP报文做了分段传输,达到目标地址后再对所有TCP段进行重组。
下面看一个HTTP包可知,如果HTTP报文过大,会由TCP自动进行分段,这个过程对于应用层来说是透明的。
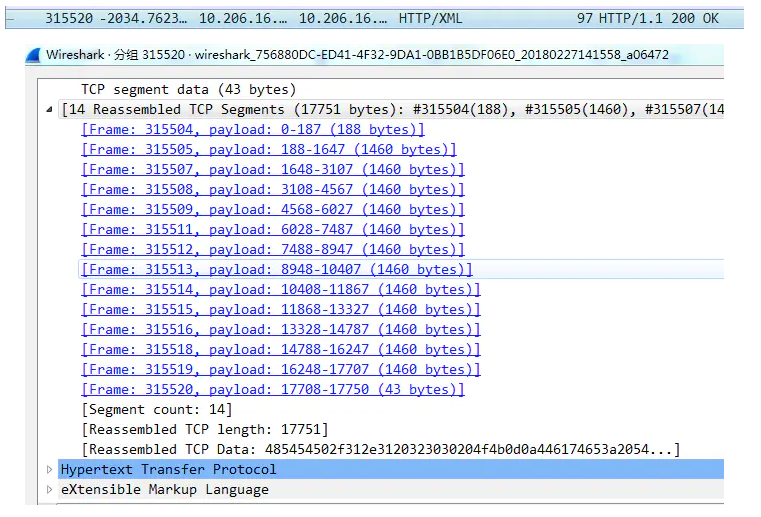
TCP 分段重组实现
TCP 重组数据包分析
参照TCP/IP详解第二卷24~29章,详细论述了TCP协议的实现,大概总结一下TCP如何向应用层保证数据包的正确性、可靠性,即TCP如何实现对数据报文的重组。
首先要设计两个报文队列,一个存放正常来到的报文,一个存放失序到来的报文。
比如正常报文队列第一个报文数据如下:
报文数据段第一字节的序号 数据报长度
seq1=100; len1=100
下一个来到的报文可能有多种情况,现依次分析如下:
1)正常报文
seq2=200; len2=200
seq2 = seq1+len1
由此报文的seq可知,这个报文携带数据序号200~399,正是上一个报文的预期后续报文,将此报文追加到正常报文队列。
2)完全重复报文
seq2=100; len2=100
seq2 ==seq1 而且 len2==len1
这个报文携带数据序号100~199,与上一个报文携带的数据序号100~199完全一样,即完全重复,所以应该丢弃这个报文。
3)重复子报文
seq2=100; len2=50
seq2 ==seq1 而且 len2<len1
这个报文携带数据序号100~149,说明这是上一个报文的一部分,所以应该丢弃这个报文。
注:第二、三这两种情况可以合并,即seq2 ==seq1 而且len2<=len1,这里分别列出只是为了说明各种不同情况。
4)部分重复报文情况一
seq2=150; len2=30
seq2>seq1 而且 seq2<seq1+len1 而且 seq2+len2<=seq1+len1
即这个报文携带序号150~179,这个序号段被包含在上一个报文段中(100~199),
所以应该丢弃这个报文。
5)部分重复报文情况二
seq2=150; len2=100
seq2>seq1 而且 seq2<seq1+len1 而且 seq2+len2>seq1+len1
即这个报文携带序号150~249,这个序号段前一部分150~199被包含在上一个报文段(100~199)中,后一部分200~249是新的数据,此时应该对这个报文作如下处理:
A. 计算重复字节数
(seq1+len1) - Seq2= 100+100-150 = 50
即这个报文段前50个字节是重复的。
B. 截取报文段新数据
丢弃这个报文段的前50字节,截取后面的新数据,即只保留字节序号段200~249。
C. 重新设置这个报文段的seq
seq2 = seq2+50 = 150+50 = 200
D. 重新设置这个报文段的数据长度
len2 = len2-50 =100-50=50
E. 重新设置后报文段如下
seq2=200; len2=50
即现在这个报文段携带数据序号200~249,正好是上一个报文的后续报文,现在可以将其作为正常报文追加到正常报文队列。
6)提前到达的报文
seq2=300; len2=100
seq2 > seq1+len1
这个报文段携带序号300~399的数据,即不是上一个报文100~199的后续报文,而是提前到来的报文,此时应该将这个报文放置到失序报文队列存储起来,以备后续重组使用。
这样直到tcp断开这个socket的链接(FIN=1),此时将正常报文队列和失序报文队列中的数据合并起来,完成重组。取出正常报文队列最后一个报文 的seq和len,在失序报文队列中查找属于它的后续报文,该报文是否可以作为正常报文队列的后续报文处理过程同前面1)~5)的分析。
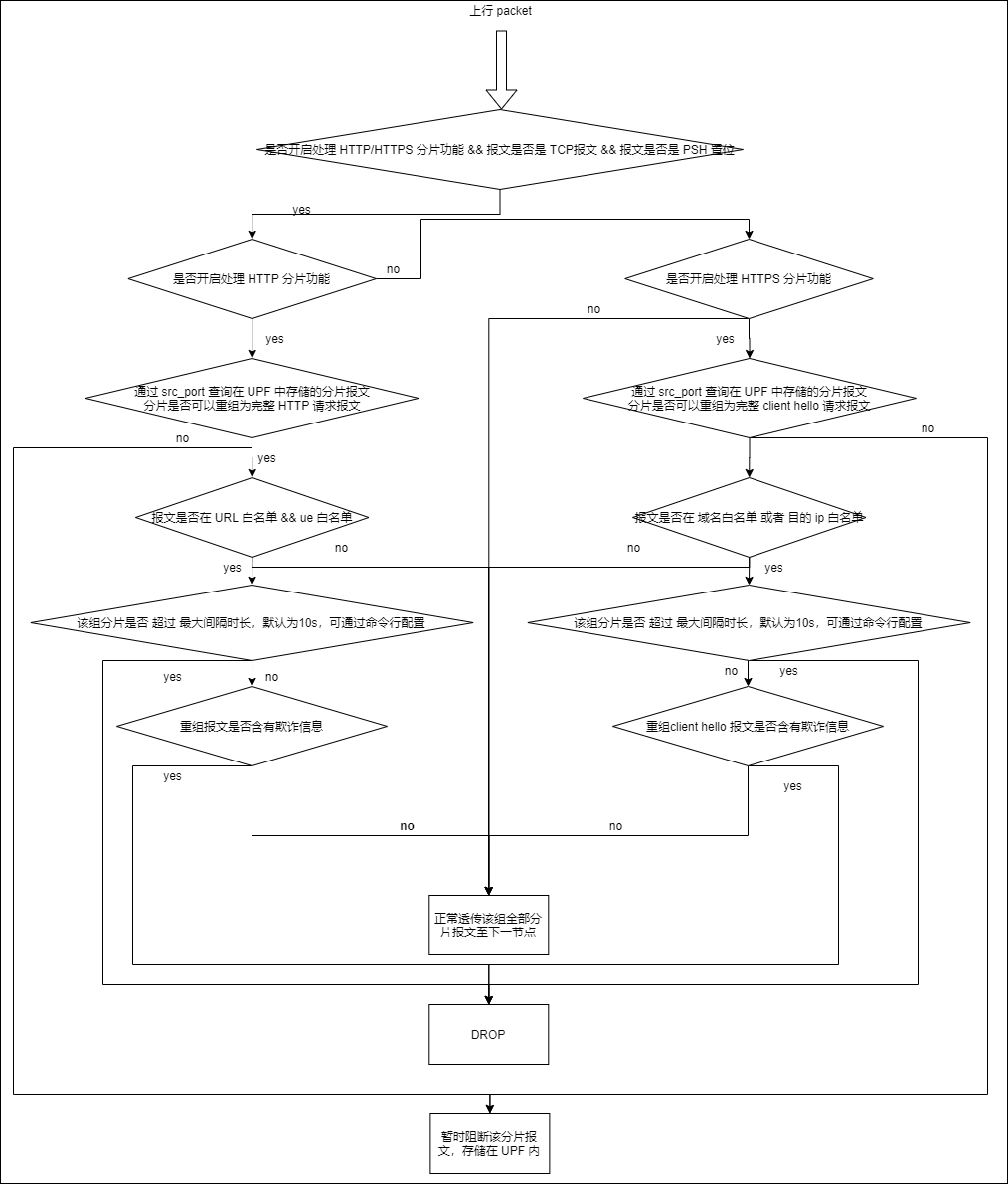
UPF 支持 HTTP/HTTPS 分片实现思路
鉴于时间关系,目前UPF支持 HTTP/HTTPS 分片主要目标为通过 CMCC 相关case;计划集采结束后,增加TCP状态机实现分片重组功能。
UPF 开启支持 分片功能后,会将所有的 TCP 分片报文做暂阻在 UPF 处理;直到分片收齐后,并做相应的防欺诈检查后,决定是否透传该组分片。
增加开启支持 HTTP/HTTPS 分片命令
upf header enrichment support segment <on|off]> http-or-https <http|https>
支持 http 分片,支持 https 分片,在同一时刻只能开启一种
# 开启支持 http 分片
upf header enrichment support segment on http-or-https http
# 开启支持 https 分片
upf header enrichment support segment on http-or-https https
# 关闭支持分片功能
upf header enrichment support segment off
增加分片超时命令
用于设置一组分片内,最后到达的分片与最先到达的分片最长有效时间;超过该有效时间的一组分片视为无效分片,做 DROP 处理。
upf header enrichment set [timeout <timeout>]
处理流程图